A Character-Counting Challenge
My recent post on the Wikimedia Commons Stroke Order Project prompted Mark of Toshuo.com to decry the relative dearth of traditional characters being added to the project. To this, David on Formosa reminded Mark that there are also a large number of characters shared by the traditional and simplified character sets.
At this point I’ll interject a visual aid (gotta love them Venn diagrams!):
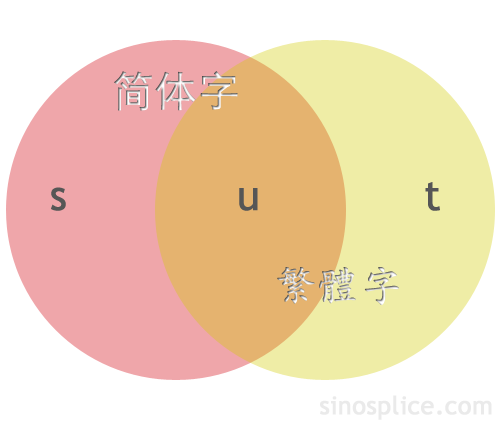
All this got me thinking about the following question: If “s” represents the characters in the simplified set not shared with the traditional set, while “t” represents the characters in the traditional set not shared with the simplified set, and “u” represents the characters shared by the two sets, then what are the number of characters belonging to groups s, t, and u, respectively?
It seems like a simple enough question, but it’s actually quite tricky for a number of reasons.
First, the total number of Chinese characters in existence varies according to source, and largely depends on how many non-standard variants you want to include in your total set. You can be reasonably certain the total number is less than 50,000, but that’s still a pretty ridiculously large number, when most Chinese people regularly use less than 5000. For basic purposes of comparison, it makes sense to limit your set to a certain number of commonly used characters, but which set? One from the PRC? From Taiwan? From Hong Kong? From Unicode?
Second, you might be tempted to think that s = t, because simplified characters were “simplified from” traditional characters. This isn’t true, however, because in many cases multiple traditional forms were conflated into one simplified form. To give a very common example, traditional characters 干, 幹, and 乾 are all written 干 in simplified. So adding these three characters adds 1 to u, 2 to t, and 0 to s. There are lots of similar cases, so clearly t is going to be significantly larger than s. But by how many characters?
I’d be very interested to see a concrete answer to this question, regardless of the character limit used. I also wonder how the proportions of s, t, and u vary as the character limit is increased, and more and more low-frequency characters are included.
If you’ve got an answer, I’d love to hear from you!
I’ve analyzed this a bit, with results here (including the tool):
http://www.hemiola.com/info.html
I didn’t take it quite as far as you sketched out, but I might now that I’ve been inspired.
What about when we factor in Japanese characters as well? How many characters are common to all 3 sets? How many do Japanese fit with simplified, how many fit into the traditional set, and how many are Japanese creations?
dmh,
Yeah, the Japanese character issue is another messy one… I was trying to keep the question simple. 🙂
Wikipedia has a nice rundown of the complications Japanese kanji bring to the issue.
Jens,
That’s really cool! So if I understand your results correctly, you don’t currently differentiate between the “t” and “u” groups, is that right?
The unihan database can be considered a reasonably definitive list of Chinese characters. Although new characters are continually being added, if they’re not in there, there’s a good chance you won’t be able to display/enter them on your computer (even the GB 18030 standard is defined relative to Unicode).
With that caveat in mind, the Unihan.txt data file freely downloadable from unicode.org contains various information for each different CJK unicode codepoint, including (where relevant) the values kSimplifiedVariant if the character has any simplified variants, and kTraditionalVariant if the character has any traditional variants (multiple variants of a given character are also specified in this field).
It’s then a simple matter of counting the characters with variants, and then removing any common codepoints (e.g. those characters that are both a traditional character in their own right, plus a simplified version of another traditional character).
which leaves us:
2667 characters that have a simplified variant (e.g. group t)
2586 characters that have a traditional variant (e.g. group s)
There was an interesting thread a while back on chinese-forums that discussed the number of characters you needed to learn if you already knew one character set, but wanted to be able to use the other. Excluding simplifications that follow a consistent pattern (説 = 说 etc), it appears there are 536 characters significantly different between the two sets.
Imron,
Thanks for the reply! So for group u, you’re saying it’s just the Unihan list total, minus 2667, minus 2586?
As for the other discussion, I think this list is useful.
I’d say I’ve only described s (2140), u (4623), and s+u (6763). But I haven’t looked at t or t+u.
In my kind of simplistic take on things, I’m simply letting the size of GB2312 represent “s+u” (6763) and what I call the primary Big5 represent the size of “t+u” (5401). I realize that’s not entirely precise (and it makes thing “not add up quite right” at the moment), but I’m just trying to look at things from a practical perspective. Except for a few swear words and such, I’m guessing you’d be hard pressed to find a native speaker who finds the standard character sets to be lacking in noticeable ways for modern language expression.
Still, I haven’t reconciled things like why/how GB2312 has 6763 characters whereas the primary Big5 set has only 5401.
I still have some files I extracted from Unihan.txt some time ago, and they give me around 80 cases of several traditional characters being simplified into one.
However, the data are not very accurate. For example, they often don’t say if a simplified character was already used in traditional (like 干 in your example, see http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%E5%B9%B2 ), but sometimes they do (like for 台 : http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%E5%8F%B0 ). Some characters my 新华字典 says are non-standard variants are considered several traditional forms of the same simplified character (like 鶿 and 鷀 for 鹚).
While I was doing that, I also noticed they have 7 occurences of a traditional character having several simplification :
Of these seven, from what I have read, only 餘: 余, 馀 seems justified in the simplification charts (余 already being used in traditional characters, there may be some ambiguities so in these cases 馀 should be used). The others look more like a confusion between synonyms (鲇, 鲶) or an application of both specific simplifications and general rules (沈, 渖).
Unfortunately, that’s where it gets tricky. The Unihan database also contains various compatibility codepoints and codepoints for other variants (e.g. 說 and 説). The simplified/traditional check was quite quick and simple to do. To get a more accurate figure for the whole thing taking into account the various other kinds of variants (see here for more info), would take more time to play around with.
You then also have to wonder how practical that is considering the Unihan database contains over 71,000 unique codepoints – most of which will never ever be used in real life. It’s all very well and good to say only 3% of characters are unique to either simplified/traditional and so you don’t need to worry, but in terms of the original problem (the Wikimedia commons) this is not so meaningful as most of those characters without a simplified/traditional variant would never be seen/used.
What you’d really want to do is look at the most frequent X thousand characters and be able to calculate those percentages for each one.
So, you’d take a list of frequency data (the ones provided by Junda are nice, but note again the differences for modern text vs imaginative text vs classical text) then take the lists of ‘simplified’, ‘traditional’ and ‘both’ that you can generate from the Unihan list, and then filter those lists for top 2,000/4,000/6,000 chars etc.
Which is not an immensly difficult task if you know what you’re doing, but non-trivial enough that I don’t have the time at the moment to do it.
@leyan, hmm yes, I checked for 台, found it to be true and so assumed it would be like that for all of them when creating my totals (it greatly simplified the work required). As such, the figures I listed will be slightly off.
I happen to have a parsed copy of Unihan in a mysql database on my laptop (just in case!), so I decided to take a crack at it.
For traditional characters, I looked at the characters in Unihan that had a Big-5 index. For simplified, I looked at the ones with a GB 2312-80 index. Then I intersected the sets to find the overlap, and summed the remaining. What I got was:
Big5: 13063
GB: 6763
Intersect: 4383
Total: 15443
I figure since if a character is neither in GB nor in Big-5 its not particularly useful (i.e., limited digital support), so they’d be good stand-ins.
@John B. That’s quite a big discrepancy though for Big5 figures when you compare it to the figures for kSimplifiedVariant.
i.e. with those figures, Big5 – Intersect = t = 8,680, compared to using kSimplifiedVariant which gives us 2667.
My guess is that the more obscure a character is, the less likely it is to have had a simplified form created. So, my naive guess would be that t is much greater than s for the most commonly used several thousand character but that the two sets would grow at about the same rate as more and more obscure characters were added.
By the way, I’ve started contributing to the Wikimedia Commons Stroke Order Project. One reason there are so few traditional characters listed is that it requires different fonts for each character set. For that reason, the simplified animation for a character can’t be copied and used for the traditional animation.
What about T/S characters that are essentially the same, but have slightly different (but not simplified) written forms? I’m thinking of 兌/兑 in particular. Does this still count as a “simplification?”
Also, John B, for an added challenge try redoing it taking into account the 43 new simplifications!
@brendan, no it doesn’t. The page I linked to above regarding variants explains this in more detail.
Brendan,
Yeah, you totally have to count those separately! My favorite examples of those are 没/沒 and 别/別.
Just to clarify my above statement, it doesn’t mean this for the data in the Unihan database. Whether they should actually be treated as simplifications is then a matter always up for debate (but I think I side with Unihan on this).
Actually, I’m wrong. Unihan does distinguish between them as T/S at least for 兌/兑, 没/沒 and 别/別
To John : “Thanks for the reply! So for group u, you’re saying it’s just the Unihan list total, minus 2667, minus 2586?”
No, it wouldn’t work, because the informations on simplification in the Unihan database were given by Wenlin, so are only relevant to the characters included in Wenlin. A lot of the 70 000+ characters on Unicode could be simplified by the general rules (like 訁->讠 or 貝->贝) but don’t appear in this stat. I don’t know the base well enough to say, but I would not be surprised if a lot of these “could be automatically simplified from very rare traditional characters” did not even make it into Unicode.
However, this does not change the value of t-s, which is the interesting part IMHO
I came up with:
s=2276
u=4487
t=2318
If you take the Gb standard 6763 simplified characters and use Wenlin to converse them to traditional you find that 4487 stay unchanged (u) and 2276 are changed (s). 36 of these 2276 change to more than one character. If you count them you get 2318 (t).