06
Jan 2022Life with Kids in the Time of COVID
As China’s COVID-zero policy drags on and on, a certain dichotomy has emerged in the population here: those without kids can still travel within China, as long as they’re aware of the “high risk regions” and plan for some extra mafan in the form of COVID testing, quarantining, etc. A lot of foreigners I know went to Sanya for their Christmas/New Year holiday. Meanwhile, those with kids (in non-international schools) are very much subject to their schools’ regulations, which essentially means not going anywhere.
So yeah, that’s me… stuck in Shanghai for the foreseeable future. My family went to Guilin and Yangshuo over the summer (when there was plenty of time for self-quarantining after travel). Travel over the Chinese New Year (CNY) vacation is possible, since kids have about 4 weeks off of school, and in non-COVID times Shanghainese families are normally quite fond of traveling during CNY rather than spending the whole vacation in Shanghai with family. But with a shorter timeframe and fewer appealing choices, it’s harder to arrange. Plus new cases (and resulting COVID crackdowns) are much more likely to emerge in the winter.
These days around Shanghai mask enforcement is quite spotty. Although many places require a mask for entry (like a mall), most won’t actually enforce the rule once you get inside. Most restaurants seem to have stopped enforcing masks altogether. Public transport and hospitals still require everyone to keep masks on at all times, of course.
As for the “health QR code” on our phones, it’s required to get into pretty much any public building, including malls and some restaurants. For a while I was getting away with using screenshots of my health code (it can take up to a minute to load the stupid code sometimes), but the app added the current time (including constantly updating seconds) to the QR code display as a countermeasure. Most of the guards at the door checking QR codes aren’t scrutinizing the phone screens they check all day long, but everyone is getting used to habitually showing a health code to get into a building. (Those QR codes are virtually never actually scanned.)
Scrolling through my photos of the past few months, I see remarkably few masked faces. It’s a strange routine we’ve settled into: only momentary mask-wearing (plus on public transit), but repeated health code checks on phones every day.

28
Dec 2021The Two Dans of the Holiday Season
Check out this holiday ad I spotted here in Shanghai:

Who is Dan, and what does he have to do with the holidays?? No, it’s actually a reference to two winter holidays.
It reads: 双dan同庆 (shuāng dan tóng qìng)
Hanukkah is 光明节 (Guāngmíng Jié) in Chinese (we wrote a bit about this on ARC), and it’s now over this year. So it’s not about that.
Christmas is now over… that’s 圣诞节 (Shèngdàn Jié). So one “dan” is in 圣诞节 (Shèngdàn Jié). The other is in 元旦 (Yuándàn), the Chinese name for New Year’s Day (which, unlike Christmas, is a national holiday in China).
So “双dan同庆 (shuāng dan tóng qìng)” means “Double dan, celebrated together,” referring to Christmas and January 1st. Try pulling off that compact linguistic wordplay in English!
Here’s something weird, though: the ad above uses pinyin “dan” to represent the two different characters both read “dàn” in pinyin. This ad, however, makes no such effort:

(Don’t be fooled by the stylization of the characters… that’s a 旦 (dàn) character, not 日 (rì).)
So the single character 旦 (dàn) is used to represent both “dan” characters, even though 圣诞节 (Shèngdàn Jié) uses a different “dan.” I’m told this is fairly common, and it’s what you do when you don’t want to insert pinyin into your Chinese text. Maybe that aversion to pinyin in Chinese text is becoming less undesirable over time?
This second ad uses the word 乐享 (lèxiǎng) which is sort of an abbreviated way of saying 快乐享受 (kuàilè xiǎngshòu), or “happily enjoy.” The quotes are there not because a character has been swapped out, but because it’s also part of the Chinese name of FILA: 斐乐 (Fěilè). Not exactly a clever pun.
Happy holidays! Here comes 2022, ready or not…

16
Dec 2021Chinese Christmas Quiz
I’ve been creating some quiz content recently and decided to do one for Christmas. I tried to make it roughly half about basic Christmas vocabulary and half about Christmas culture in China.
One thing that became clear to me while putting together this little quiz is that this culture changes so fast.
Christmas was getting super popular at Shanghai’s kindergartens and elementary schools, with some schools even bringing in a guy dressed up as Santa. But Beijing put the kibosh on that in recent years, opposing such strong “advocacy” for foreign culture in schools. So now, even though Christmas is as popular as ever commercially (there are Christmas trees and decorations all over Shanghai’s many malls), it’s not allowed in schools.
Christmas choir concerts at Christian churches in China were once very popular, even among young people that would typically not go to a church for any kind of religious reason. But as a Christmas activity for fun, to soak in a little extra Christmas ambience, it was popular. But COVID has greatly complicated gatherings in churches, meaning that this year it’s pretty safe to say that all of those performances are canceled.
China remains as dynamic as ever. Christmas is no exception.
So how much do you know about Christmas in China, and Christmas and Chinese? Take this little AllSet Learning quiz and find out…
08
Dec 2021Chinese Christmas Songs: Free MP3s for the Holidays
These are always popular in December, and I can’t believe I forgot to share them last year. Well, they’re back!

Sinosplice still has some awesome familiar Christmas songs in Chinese. This year I’m again posting a selection of the MP3 files online in streamable format, so be sure you’re viewing the original post on Sinosplice.com if you’d like to play the songs without having to download everything.
All right, here we goooo…
Jingle Bells in Chinese
This is version 1 from the album (Mandarin Chinese):
Jingle Bells in Hakka (Hokkien) Dialect
This song is not part of the album because it is NOT Mandarin Chinese. It’s Hakka. (This one is going to have very limited use for most students; it’s just sort of a novelty for most of us.)
Santa Claus is Coming to Town in Chinese
This one is a kids’ version, version 2, also from the album (Mandarin Chinese):
Santa Claus Is Coming to Town (2)
We Wish You a Merry Christmas in Chinese
This song is especially beginner-friendly for learners of Mandarin Chinese (that chorus!):
Silent Night in Chinese
This one is a Christian classic, of course, version 2 from the album (Mandarin Chinese):
Hark! The Herald Angels Sing in Chinese
Another Christian classic, church choir style (Mandarin Chinese):
Download Christmas Songs (zipfile)
If you want to just grab them all, here you go:
The Sinosplice Chinese Christmas Song Album (~40 MB)
+ Lyrics PDFs (1.2 MB)
Disclaimer: I don’t own the rights to these songs, but no one has minded this form of digital distribution (in the name of education) since 2006, so… Merry Christmas?
MP3 Track Listing
- Jingle Bells
- We Wish You a Merry Christmas
- Santa Claus Is Coming to Town
- Silent Night
- The First Noel
- Hark! The Herald Angels Sing
- What Child Is This
- Joy to the World
- It Came Upon a Midnight Clear
- Jingle Bells
- Santa Claus Is Coming to Town
- Silent Night
- Joy to the World
Merry Christmas everybody… 圣诞快乐!
While we’re on the subject of Christmas and Chinese, AllSet Learning (my company) is doing some special offers with our live, 1-on-1 online Chinese classes. 3 lessons (one hour each) is a great quantity to try it out or gift to a loved one, and we have larger packages for the more ambitious learners as well.

01
Dec 2021A Shiny Pun
A pun in a jewelry ad:

Here’s the text:
就“耀”此刻
It’s a very simple pun, although the words and characters involved are somewhat advanced.
“耀,” as in 闪耀, meaning “to glitter” (or even 炫耀, meaning “to flaunt”), is a substitute for 要, meaning “want.” 此刻 is a formal way of saying “this moment.”

26
Nov 2021The MVT for Thanksgiving
Back when I was teaching at Zhejiang University City College in Hangzhou (2001-ish?), I taught a course called American Society and Culture. I also had to introduce Thanksgiving. My students were especially interested in the food, so I found myself with an interesting task: coming up with a core set of dishes for an American Thanksgiving dinner.
Put another way; what is your Minimum Viable Thanksgiving? I mean, sure, you could get all sentimental and sappy and talk about your family and loved ones, but this post is about FOOD! Focus, please.
The list I came up with included these 5 must-haves:
- Turkey
- Stuffing
- Mashed potatoes
- Cranberries (in some form)
- Pumpkin pie
Then I’d make corn, green beans, and pecan pie runners-up, maybe.
Here’s an interesting fact: if you’re like me and eat out for Thanksgiving in China, even in Shanghai in 2021, it’s kind of hard to find a restaurant that will include all 5 of these items on their Thanksgiving menu. It seems like they always omit one of those core items. (This year it was pumpkin pie that my restaurant of choice left out, but fortunately I got some from another source.)
Anyway, this did get me wondering how many Americans would agree with my list. What would you sub in/out from the list of 5 MVT items? (Sound off in the comments!)
And, because my life is all about Chinese learning resources, here are some images with Chinese:





17
Nov 2021Card Games for Language Learning
It was last year that I bought the card games Language Guardians 3 and Fighting Flashcards. It wasn’t until last week that I put together a group of people to test them out. It was a good time!
Thanks to Akeel for help organizing, and to Vaughn and David for joining in. Here’s our group in the AllSet Learning office lobby:

Game 1: Language Guardians
This game is sort of like Uno in that you have a number of colors (which correspond to language tasks) and a number of card types (which correspond to word categories). If you know Uno, this game is super easy to pick up.
I should note that the number is actually quite important, in that “Language Guardians 1” is meant for elementary-level players, whereas “Language Guardians 3” is much more advanced. We used a little “equivalency chart” so that we could mix the categories of 1 and 3, and different level players could all enjoy the same game.
So, for example, when the LG3 “monsters” card came up, an elementary-level player could sub in the LG1 category “animals.” It worked just fine. There was lots of learning from each other. Good times!
Game 2: Fighting Flashcards
This is the game I was most excited to try out because it plays kind of like Magic: the Gathering, except that each player has his own stack of flashcards to work through. When you’ve worked through your flashcard deck, you win!

At this point, we were running short on time. So for this one, I played “game master” in order to keep the game moving smoothly.

It was our first time playing the game, so we were still getting the feel for it, but the interplay between the game cards and the flashcards was super interesting. Over the course of the game, it became quite apparent how powerful some game cards were, and that you could adjust the “balance of power” between game cards and flashcards by omitting certain game cards from the deck.
Flashcard Considerations
The cool thing about Fighting Flashcards is that each player uses his own deck of cards. So by bringing the cards you’re working on, you customize the game to your own level, and players of different levels playing together is no problem. Pretty slick.
BUT, what if one player brings flashcards he already knows 90% of, and some other player ambitiously brings flashcards he only knows 40% of? Obviously, it’s not going to be a super fair match-up.
To compensate for this, I told the players they didn’t need to provide their own flashcards. I provided blank flashcards which we would use to make new flashcards right before the game started.

I provided some HSK word lists and AllSet Learning themed word lists, and each player was able to select a source of vocabulary which was both level-appropriate and interesting to him personally. Then, another player would choose words from a player’s list, providing some randomness and potential challenge. After quickly making 20 flashcards for each player, everyone had about 5 minutes to quickly review his own words before kicking off the game.
Igniting Imagination
As an educator and gamer, the part I loved most about this exercise was the way it ignites your imagination. The game instructions themselves encourage you to try different variations, use only certain cards for certain game types, etc. But just playing the games results in all kinds of ideas for twists on the games, ways to practice different language skills, ways to use flashcards, and so on.
One of the ideas we had when playing Fighting Flashcards was for each player to use his own phone to do electronic flashcards. But the game itself requires paper flashcards because it has multiple cards requiring you to shuffle your deck, or go through the flashcard discard pile, etc. So that didn’t work, but it’s not hard to imagine a variation of the game which would work with electronic flashcards (or maybe even a new flashcard app that supports games like this?).
Sure, anyone could create their own language learning games with pen and paper, but having these fully realized games in front of you really sets the stage so for quickly building on what’s already there with new ideas.
More Info on the Games
Full Disclosure: I got in touch with Matthew at LanguageCardGames.com before buying the card games, but I did buy them, and I don’t earn any kind of affiliate income from the links in this article. If you’re intrigued and have the means to do so, please support Matt and LanguageCardGames.com!
Also, since I didn’t go into gameplay much in this article, if you’re interested in learning more about how the games work, then definitely check out the website. Matthew has multiple gameplay videos on YouTube showing different games in action, and with different languages too.
12
Nov 2021Easy-to-Read Signs around Shanghai
I was recently walking around Shanghai near the Bund (west side of the river), and realized that a lot of the sign names there are super beginner-friendly. This is actually kind of rare, so it’s worth pointing out.
Here’s one for you, beginners!




A few notes:
- Having the cardinal directions (东、南、西、北) on the street signs is actually super useful. I use this constantly while walking around, and it’s actually pretty hard to get lost (even what your phone is dead!).
- I didn’t realize this when I first came to China, but a ton of street names in many cities are just names of other cities in China. So you might assume for a long time that a street name like 九江路 is some kind of poetic “nine rivers street” made up for Shanghai, but no. You’d be wrong. Jiujiang is a city name.
04
Nov 2021English Randomness from Shanghai
A t-shirt on the light rail escalator:

A soup shop sign. The part I love (because it’s hilarious), reads, “Soup is the new coffee.”

Ear cleaning (yes, it’s a thing, considered more like a massage than a… dental checkup or something else unpleasant):

02
Nov 2021Chinese Number Sudoku
Every now and then I came across an idea that is brilliant in its simplicity. This is one of them: Chinese number sudoku!

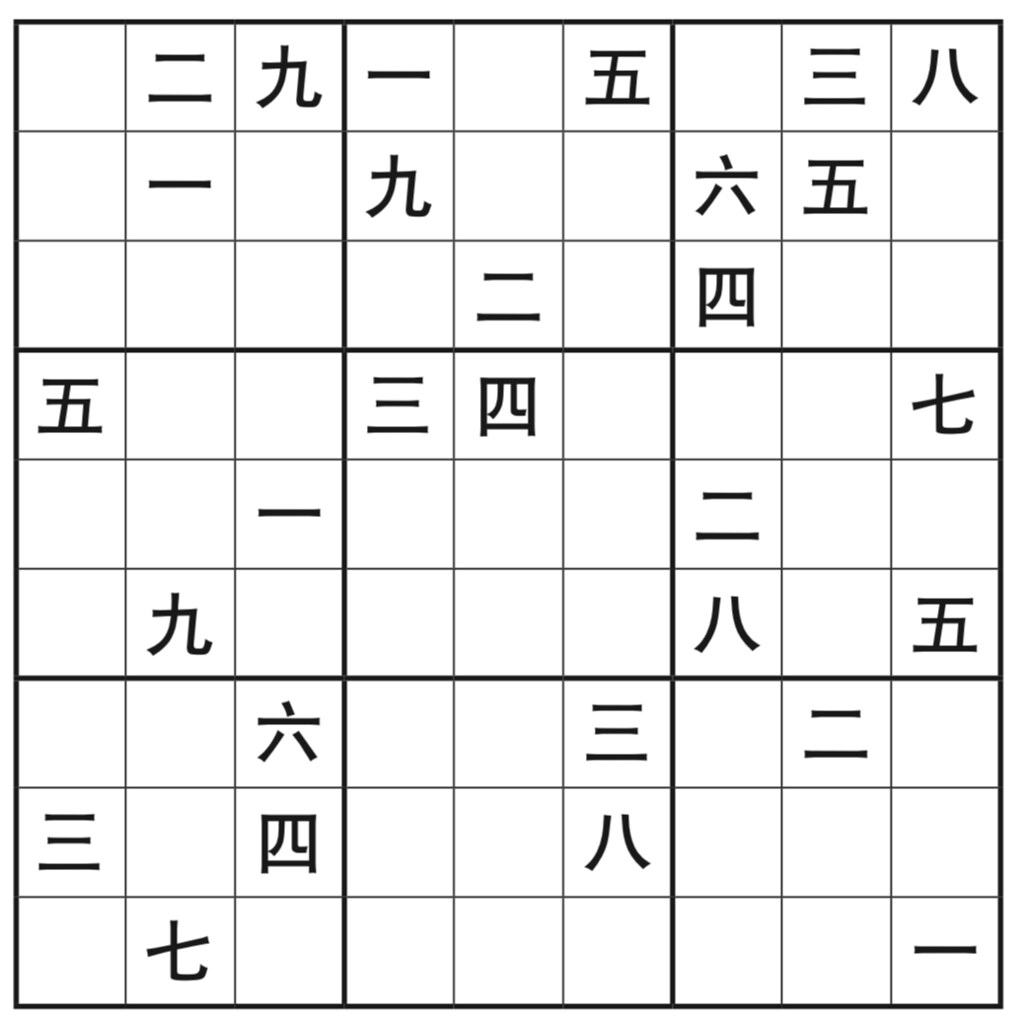
So it’s just sudoku (数独 = sudoku = shùdú), but using the Chinese characters numbers 1-9: 一、二、三、四、五、六、七、八、九.
If you want to improve your handwriting in Chinese, it can be hard to come up with a way that isn’t mind-numbingly boring. Well, if you like sudoku, this should do the trick.
(Technically you could do this with any set of 10 characters; they don’t even need to be numbers. I imagine it’s very difficult mentally, to pull off, though, if they’re not in a very clear sequence.)
Anyway, these images come from the book Chinese Sudoku by Earnshaw Books (posted with permission), and it’s also on Amazon.
27
Oct 2021Boozy Latte Brings the Bad Pun
Saw this ad in my neighborhood here in Shanghai:

I’m of the opinion that this quite a bad pun. My Chinese friends and co-workers agreed. The text that the ad copy sounds kinda like is;
我就爱这样
In other words, “i just love this.” The ad also “subtly” communicates with the “酒” that there’s alcohol in there, while broadcasting that they’re going after the “young” demographic as well.
The thing is, this latte drink contains no alcohol… it’s just 酒香 (alcohol-scented). Maybe that’s kinda like the fake rum in rum raisin ice cream? I dunno.
I’m not buying any of this on any level! (Oh, and this is the same robot coffee that I’ve blogged about before.)
21
Oct 2021When a Window is a Door
What’s the old saying? “When God shuts a door, He opens a window?” Not sure if that applies here, but this is the “door” of a small clothing shop here in Shanghai:

That’s right, you step on the little footstool and climb in through the window. There is no other door that customers have access to.
Shops like this used to have their storefronts on the street, spilling out onto the sidewalk. These were the charming little local shopping options that China is known for. But in recent years, the government has been closing many shops like that, and even bricking up patios that used to be used to (technically illegally) sell stuff.
But bricking up a storefront doesn’t always mean that you can’t sell stuff at all. As you can see.
P.S. This is not a new phenomenon. I just haven’t commented on it before, and happened to snap this photo the other day.
14
Oct 2021Bickering Butterflies in Pleco
Most learners of Chinese know about Pleco, the popular Chinese dictionary. One of its great features (especially for long-term serious learners of Chinese) is that you can have multiple dictionaries within Pleco. This can provide wider coverage and a lot more depth. But every now and then, this feature can potentially be the source of confusion.
Check out this Pleco entry for “butterfly” (蝴蝶):
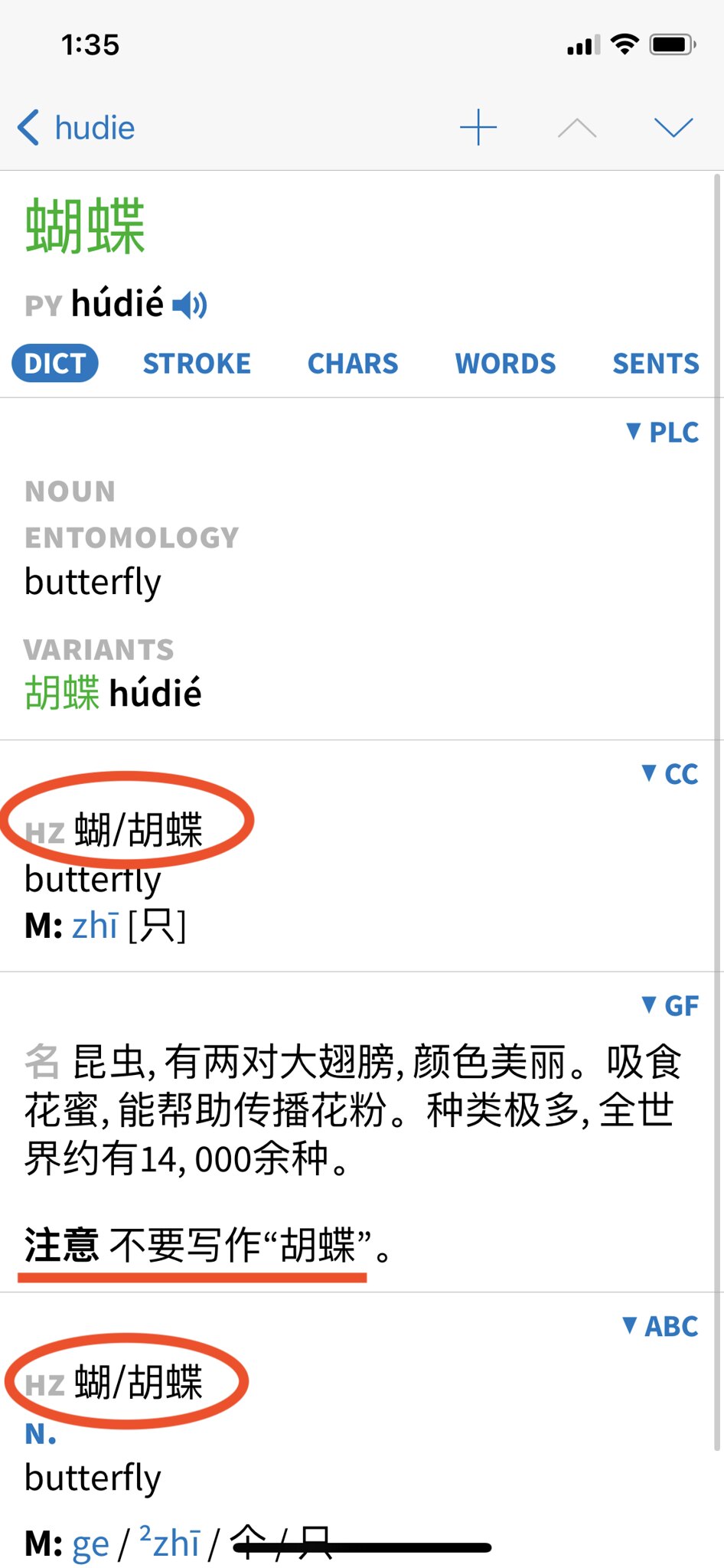
Confused? It’s like the dictionaries are arguing amongst themselves.
PLC: It’s 蝴蝶.
CC: Actually, both 蝴蝶 and 胡蝶 are OK.
GF: DO NOT WRITE 胡蝶!!!
ABC: Whatevs. You can write 蝴蝶 or 胡蝶.
My Chinese co-workers say that 胡蝶 can be a woman’s name, but not a butterfly. Not sure what the source of contention is here. (If you know, feel free to share in the comments!)
08
Oct 2021The Fruits of Peace: IN YOUR FACE!
This propaganda poster cracks me up every time I see it around Shanghai:

The Chinese reads:
严惩黑恶势力 (Yánchéng hēi‘è shìlì) Severely punish evil power
共享平安成果 (Gòngxiǎng píng’ān chéngguǒ) Share the fruits of peace
OK, so I’m not really trying to make that propaganda sound less ridiculous in English, but look at that picture. That’s “super police” (his chest has a 警 in it for 警察, “police”). This is “sharing the fruits of peace”?
I have to chuckle, wondering if the copy writer had any clue what the illustration would be like.
28
Sep 2021The Garlic Hangover
After a Saturday night of delicious Mongolian hot pot (涮羊肉) particularly heavy on the garlic, I had that familiar feeling when I woke up in the morning: my whole mouth reeked of garlic, and even my tongue itself felt and tasted like a marinated chunk of garlicky meat. This stubborn garlic imprint took over 24 hours to fade. (And yes, I brushed my teeth. Multiple times. That gave me minty garlic breath.)
The thought came to me: this is a garlic hangover. But I was not the first one to come up with this term… it’s already in Urban Dictionary.
How common are these garlic hangovers for my garlic-loving friends in other countries? I don’t know, but in China it’s especially common when you eat hot pot (火锅) or the variation of hot pot known as Mongolian hot pot (涮羊肉). It’s because you “mix your own sauce,” and you’re given free reign to liberally dump the minced garlic (蒜泥) into your sauce bowl. And liberally dump I do!
Here’s what the minced garlic looks like (but usually there’s more of it):

Then when you mix your sauce, it might look something like this (although mine is typically more of a brown/red spicy color):

So then you’re dousing meat and veggies in that sauce all meal. And if you’re anything like me, you’ll need to whip up another bowl of sauce halfway through the meal.
Finally, for those unclear, I’ll share a picture of Mongolian hot pot (the bundt cake of hot pots):

(Note the sauces hiding “innocently” in the back. Don’t be fooled!)

16
Sep 2021Movie Titles in Chinese: Translations or Labels?
I enjoy examining the translations of brand names, book titles, and movie titles. They’re important for many reasons, so quite a bit of thought should have gone into their selection. Indeed, many translations of this kind are brilliant and well worth studying. One glaring exception, though, are the names of many Hollywood movies released in Mainland China.
I’ve mentioned before that American animated films in China have some of the “laziest translations ever,” blatantly overusing the words 总动员 and 疯狂. In this article I want to talk about another phenomenon: 玩家 (literally, “player”). This one is not nearly as overused, but it’s conspicuous for several reasons.
Free Guy: 失控玩家
The movie title I’m focused on here is the Chinese translation of the new Ryan Reynolds movie, Free Guy. In Chinese, the name is 失控玩家, which is literally something like “player out of control.” (WARNING: my analysis may involve very mild spoilers (but nothing that spoils the ending.)
If you know anything about this movie, you know that it’s about an NPC (non-playable character) in an online game who becomes self-aware and “goes rogue.”
Here’s the thing: an NPC is, by definition, not a player. A character that is non-playable is not a player. That’s kind of the point, and this point does drive the plot in some places. So while “失控NPC” (“out of control NPC”) would be appropriate, 失控玩家 is not. This may seem like nitpicking, but it’s not a minor issue if you’re a professional tasked with titling the movie. It’s almost as if the “translators” for the movie title never watched the movie and just took a guess as to what it was about. (?!?!)
Now there are “players” in the story that play an important role in the plot. But these players are not 失控玩家. The only other character in the story that could be said to 失控 (lose control) would be the founders of businesses or games that lose control of their “creations” during the story. But in those roles, they’re not “players” either.
Interestingly, the Taiwanese name for the movie is different but essentially makes the same error:

脱稿, in this case, means “to go off script.” So, again… it’s the NPC going off script, not a player.
Why the 玩家?
So the question is: why force the use of 玩家? What’s the end here?
It does make me think of another movie that was fairly popular at the Chinese box office in recent years. Ready Player One‘s Chinese “translation” is 头号玩家.

Although not as severe, this movie title has its own translation accuracy issues. First of all, 头号玩家 means “number one” in the sense of “best.” So it doesn’t mean “Player #1”; it means “the best player.” The text “ready player 1,” which displayed on the screen before player 1’s turn to play a game, may not be as familiar to a Chinese audience, since many Chinese kids grew up playing on pirated gaming systems that were in other languages, and modern gaming systems don’t tend to use the “take turns playing” mechanic anymore. So there may be no way to translate “ready player one” that would be familiar to a Chinese audience like “ready player one” is to a video game-loving American audience. Given that context, the translation choice makes more sense.
Crucially, though, the word “player” is in there. 玩家.
A co-worker pointed out to me that around the same time, a Chinese movie called 幕后玩家 (literally, “player behind the scenes”).

Related? Uncertain.
Movie Title Keywords as Labels?
So this got me thinking about the “translation trends” we’re seeing here in China. Could it be that rather than just being “lazy” or bad,” the higher-ups in charge of the translation selection are opting for purely functional titles that don’t consider translation fidelity a priority? The idea is that when you add in 总动员 or 疯狂, you’re communicating to the market very clearly: this movie is a cartoon for kids. When you include 玩家, maybe it’s something like, this is an action movie related to video games?
It seems incredibly patronizing to the Chinese audience. This audience is clearly sophisticated enough to learn what a movie is about and make a decision on whether to buy a ticket or not, without the aid of a “movie title keyword,” right?? One would think so.
It’s worth noting that plenty of movie title translations in China don’t follow this trend, such as all of the Marvel movies. But the Marvel brand can sell tickets on its own. The “movie title keyword” approach seems to be a card that’s played when a one-off movie with no connection to known franchises appears.
Will this bank of “movie title translation keywords” continue to grow? Time will tell.
12
Sep 2021Migrating to a New Webhost
No time for blogging this past week, as I’ve been busy migrating my websites away from Webfaction. I’ve really enjoyed using that webhost over the years, but they’ve since been acquired by the vile behemoth GoDaddy.
So now I’m migrating to a new little upstart company very much like the old Webfaction called Opalstack. Seems like a great company so far.
This is my last post out of Webfaction. Blogging to resume shortly from Opalstack…

02
Sep 2021Key Word of the Month: jianfu
I’m hearing the word 减负 (jiǎn fù) nonstop these days. Of course, it’s largely because I’m a parent with two kids in the Shanghai primary school system, but it’s still a big topic with huge implications for all of Chinese society.
减负 (jiǎn fù) is actually short for 减轻负担 (jiǎnqīng fùdān), literally, “lighten the burden.” It refers to students’ burden of schoolwork. You sometimes hear the term 双减 (shuāng jiǎn), literally, “double reduction,” because recent policies reduce both students’ homework and their after-school extra-curricular studies.
Major Changes in Education
Last month a new law suddenly greatly limited what extra-curricular classes in math, Chinese, and English were allowed to be offered by private companies. These topics are now to be covered solely by the school system.
Yesterday the school semester started, and elementary students’ homework has been drastically reduced, supposedly to 30 minutes or less. First and second graders should have no homework at all.
Is this possible? Is this even China??
Already I’m seeing some interesting responses:
- My daughter came home yesterday with instructions from her teacher for the parents, telling us to be sure to fill out “0-30 minutes” as the amount of homework she did in the official questionnaire all parents have to do daily through WeChat.
- On day one of the new semester, there is already talk in the classroom about students not having to take final exams this semester, if they get high enough grades. But can they even get high enough grades with so little homework? Is there subtle hinting going on here?
Why?
It would be nice if the only reason this was being done was the well-being of the students. But of course there are other motivations.
The main motivation I keep hearing is to encourage the population to have more children. Simply changing from a One Child Policy to a Two Child Policy (and then a Three Child Policy) does not achieve the desired results anywhere near quickly enough, and the population is aging rapidly. More has to be done to reduce the social momentum of the One Child Policy.
The cost of education is one of the major reasons it’s so expensive to raise a child in China, but if all the extracurricular class costs are cut out, the financial burden on parents is drastically reduced. At the same time, the parents’ burden to hound their children every day, all evening to finish homework is also drastically reduced.
Of course there are other theories… theories which some parents I talk to have labeled “conspiracy theories.” Stuff like reducing dependence on outside sources of education also reduces exposure to non-Chinese, non-party-approved channels of information. It’s a step closer to total control of the education system (and thus the minds of the new generation). Crazy?? Hmmm…

25
Aug 2021Just Launched ARC (Advanced Readings in Chinese)
Here’s a quick summary from the AllSet Learning blog post:
Each newsletter consists of roughly 5 short pieces (excerpts of longer articles, which are cited and linked). The 5 pieces typically consist of:
- a news item
- a “social trends” item (less time-sensitive, more focused on modern China and “the buzz” currently en vogue)
- a visual piece
- an alternative piece related to art, poetry, music, propaganda, or something else
- a joke
(If this stuff reminds you a little bit of Reader’s Digest, or the Chinese version 读者 (Dúzhě), you’re not crazy! There was definitely some inspiration drawn from those.)

Advanced learners, head on over to the Substack ARC newsletter page and check it out!
18
Aug 2021Emergency Toilets (Guilin)
Spotted this sign in Guilin:

This is not Chinglish. This is not bad translation. This has got to just be someone’s idea of a joke.
What the Chinese actually says is:
应急避难所 (yìngjí bìnànsuǒ) emergency shelter / place of refuge in an emergency
I feel a little bad for the foreigner sprinting for a toilet like the guy on the sign, and unable to find one in time…
(It is kind of funny, though!)