16
Apr 2012Sinosplice is 10 years old

It’s hard for me to believe, but the Sinosplice blog is already 10 years old today. My first post was April 16th, 2002. You can see 10 years of blog posts all on one page.
Through my early “China is so crazy” observations, to my English teaching posts, to my move from Hangzhou to Shanghai, through my Chinese blogging experiment, to my 3 years in grad school in Shanghai, to a stronger focus on Chinese pedagogy and technology, the only thing that’s really remained constant has been the “China” angle.
But what do I take away from the experience after blogging here for 10 years? Well, it was totally worth it. It wasn’t always easy to keep blogging all these years, but I’m totally glad I have. I frequently tell people that this is one of the single most rewarding activities I’ve ever devoted time to. It’s not that it was non-stop fun, or that it made me rich or made me into a great writer, but it’s connected me with people in ways I never expected. I met some of my best friends through my blog. I got my job at ChinesePod in 2006 through my blog. I’ve made many professional contacts through my blog, and it’s a great channel for new clients to discover my work at AllSet Learning. None of this was planned!
Nowadays blogging feels very corporate, or if independent, usually highly niche. When you look at the Sinosplice blog archive as a whole, it’d be hard say my blog is niche, because it’s changed so much over the years. Content, design, readers… it just keeps changing. I think a certain degree of flexibility with one’s theme is an important ingredient to keeping a blog alive long-term; when you’re overly focused you can write yourself into a corner and run out of things to say (or you just get bored).
So I’d just like to end this post by saying thank you to my readers, past and present, and to encourage those of you out there to put your voice online if you’re at all tempted. You don’t have to have an amazing start, and you don’t even have to be fiercely niche, but somewhere along the way you may find you have a lot to say, and keeping at it can really pay off in unexpected ways.
13
Apr 2012The Perils of “This Week” and “Next Week”
Sometimes Chinese seems to warp the fabric of space-time. It’s true; culture can warp our perception of reality with Sapir-Whorfian aplomb. I exaggerate, though; I’m talking about interpretations of the phrase “this week.”
At the crux of the matter is the fact that the Western American week starts on Sunday (星期天), whereas the Chinese week starts on Monday (星期一). Most of the time this causes no problems… Unless you’re trying to make plans for the next 7 days on a Sunday. This is such a simple matter; it shouldn’t be so confusing. But if you forget that this discrepancy exists, misunderstandings abound. It’s embarrassing, but I admit: even after all this time in China, if I’m careless in my thinking, I still make this mistake occasionally. (The key is that one doesn’t often make plans for the coming week on a Sunday.)
Here are some diagrams to make the issue clearer:
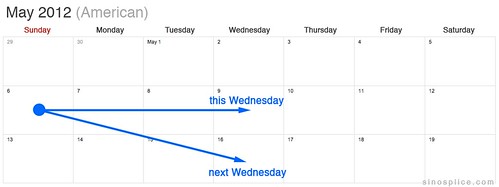
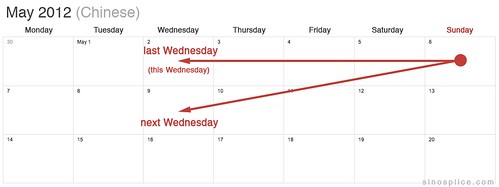
So, in the examples above, if I say “这个星期三” on a Sunday, thinking I’m referring to the coming Wednesday (May 9th), I’m actually referring to the past Wednesday (May 2nd).
OK, now here’s the annoying part (for us native speakers of American English): the Chinese way is more logical. Here’s how it works:
1. If you refer to any day of last week (even if it’s yesterday, technically), you use 上个.
2. If you refer to any day of this week (Monday through Sunday, even days already past), you use 这个. It just means, strictly, “of this week.” No ambiguity.
3. If you refer to any day of next week (even if it’s tomorrow, technically), you use 下个.
As long as you remember that the week starts on Monday and not Sunday, it’s all very consistent and logical. The reason this is confusing to non-native speakers like me is that the system that we use in American English is kind of a mess. I hear that many British speakers follow rules that are basically the same as the Chinese ones, but I know from experience that the system used in the USA is much more muddled (examples here, here, and here).
OK, it’s not actually that hard. I’m not trying to add a new item to “Why Chinese Is So Damn Hard.” But it’s a pretty bewildering experience when it happens to you the first time. The joys of intercultural exchange!
Update: In the original post I said “Western” when I should have said “American.” Apologies for the inaccuracies. The point of the post still holds true (particularly for us Americans).
05
Apr 2012Journey: East Asian/Islamic Design Mashup
The PS3 game Journey has recently been released to rave reviews. Here’s a little taste of what people are saying from the Escapist:

> It’s not something you can commit to words, really, it’s something you have to feel. Should you choose to play the game – and I really hope you do – your trek through the ruins will be a very personal experience, the impact of which only you will truly understand. It won’t change your life, but it just might change your thoughts about what videogames can accomplish.
The review above is fairly typical. The word “magical” tends to come up a lot in other reviews. Clearly, the game is extremely well designed, and people are duly impressed. But at the heart of the design is a fascinating mashup of Chinese, Islamic, and even Tibetan design elements. I was a bit disappointed that I’ve so far been unable to find any in-depth coverage of the design inspiration for this game. My original impression was something like: aliens + mosques + 8-bit + Chinese characters + Lhasa.


It’s probably the alien glyphs that impressed me the most. They have an 8-bit style, and the (sort of Moroccan?) desert setting guides your mind to the idea of Arabic calligraphy, but the style of the characters themselves tends more toward over-grown Hebrew letters. Each glyph has a clear four-part internal structure to it, though, which feels like a nod to the structure of Chinese characters. Later on in the game, you end up in a temple level, where the glyphs are covering the walls in a neat grid, and it definitely felt like some of the places I’ve been in China.


The game Journey is a rather obvious metaphor for life, but the mix of religious themes is striking too. Mosque elements are blatant in the beginning, and snowy mountain monasteries at the end, but the single culture woven throughout the game is consistent, and there are ongoing themes of meditation and murals of spiritual significance. No “religion” is ever mentioned (in fact, the glyphs and beautiful music are the only “language” that appear in the game), but the intensely personal nature of the quest and the white-clad enlightened ones returning to help the new pilgrims (a game mechanic built into the game’s trophies) feels very Buddhist.


The makers of Journey wanted to do something different with Journey by innovating around the emotional response a game could evoke. In this way, games can appeal to wider audiences, and perhaps even come closer to “art.” But Journey is a worthwhile experience for anyone interested in Middle Eastern or East Asian culture, especially from a design perspective. The writing system alone is worth admiring. If you have access to a PS3, check this game out.


03
Apr 2012Exit HSK
I recently met up with an old friend who said she had started studying for the HSK. The conversation went something like this:
> Me: Wow, the HSK, huh?
> Her: Yeah, I know… I felt it was finally time.
> Me: So you’re planning on leaving China soon?
> Her: Uhhh… I didn’t say that…
> Me: Yeah, I know, but if you’re not planning on doing some kind of university program here, the main reason to take the HSK is to get a score for your resume.
> Her: Exactly. I’ve gotten my Chinese to a decent level here, but I don’t have any kind of degree in Chinese, so I figured it was time.
> Me: So are you leaving?
> Her: Not sure yet, but possibly.
Few see the HSK as a useful test. It’s a necessary evil for certain purposes. HSK test prep is definitely not very helpful for improving one’s communication skills. It sure is ironic that for many, it has become the test you take when you decide to leave China.
28
Mar 2012Awesome Speech Habits of Americans
I’ve been slowly reading through Professor Orlando Kelm‘s book, When we are the foreigners: What Chinese think about working with Americans, and right in the first chapter I was highly amused by this passage:

> Recently, Mr. Jorgensen has been working closely with Xiaoliu Li, the human resources manager for TPC China. Upon entering her office, an aura of competence is immediately apparent. Young, pretty, polished, professional, and easy to engage in conversation, Xiaoliu Li gives the impression that she loves her job. In fact, Mr. Jorgensen usually introduces her to others by saying, “I’d like you to meet our highly competent human resources manager Xiaoliu Li.” Almost sheepishly, she acknowledges the the introduction, always noticing, however, how extraordinary it is to hear “highly competent” when making an introduction. Those types of phrases are, in fact, one of her observations about Americans. “You Americans think everything is great, wonderful, fantastic, amazing, cool, or awesome.” Not only do Americans think everything is awesome; they also say so, using these terms in both casual and formal conversations. That style of speech and feedback seems out of place among Chinese. “Chinese aren’t prone to use those types of words when describing people,” observes Xiaoliu Li, “much less when directly talking to them.” Basically, My. Jorgensen is oblivious to the effect of the way he uses vocabulary. To him, it’s just a matter of having a positive attitude.
My wife has made almost exactly the same observation. She claims that it’s hard to know what Americans really feel about something because everything is “great” or “awesome” or “amazing.” (This is, of course, the opposite of what is often said about the Chinese, who always seem to be “hiding their true feelings,” forever inscrutable to most foreigners.) So to her, it’s not that Americans “think everything is awesome,” it’s that they say everything is awesome, which can, in her mind, only be construed as (at least a mild form of) insincerity. So I guess that’s what we Americans get for being positive and enthusiastic about life: suspicion of insincerity!
Anyway, I’m enjoying this book, because instead of trying to make blanket statements about culture, it takes the case study approach and shares real people’s views on real incidents. (Now if only I had more time to read…)
23
Mar 2012Ramen by Infographic
I was introduced to this ramen infographic recently by the creator.
Ramen (ラーメン) is actually Japanese, but it has (somewhat unclear) historical connections to Chinese noodles, which could possibly be either lamian (拉面) or lo mein (撈麵 / 捞面).

Created by: HackCollege.com
20
Mar 2012Big Fat Rent
The style of the character “租” (meaning “rent” as in “for ~”) below really jumped out at me when I saw it in a store window:

Amazing how good a simple sign can look when the handwriting looks good…
15
Mar 2012Interview with Rachel Guo of No Drama Real China
Everyone seems to really enjoy No Drama Real China, so I thought I’d follow up my last post with an interview of the creator, Rachel Guo…
John: What inspired you to start No Drama Real China?

No Drama Real China host Rachel Guo
Rachel: It’s a long story. My very first trip to America was on July 7, 2011, and the first thing that surprised me the moment I stepped out of JFK airport in New York was how familiar everything was to me! Yes, I watched too many American movies, TV shows, and everything for years, and I even have a little bit of an American accent. What a powerful soft power! And after 40 days of travel in New York, D.C, Seattle, LA, San Francisco, Santa Barbara, and a small town two hours from the Canadian border in Washington, I found the other thing that SURPRISED me was that many Americans know so little about China, they asked me questions like:
– “Are there highways in China?”
– “How do you come here? Yes, i know by plane, but HOW?!!”
– “I heard a story that many Chinese families saved money for years so they finally could afford a refrigerator, but then the refrigerators they bought all broke after a while. So the Minister of the Labor Department ran into the refrigerator factory and shot the factory director because they produced bad quality products.”
There’s a lot of drama surrounding China, but where does it all come from? Form the media, American newspapers, and the Internet, which focuses on attracting attention to China’s problems and abnormal things. Some people see one drop of the ocean and think it IS the ocean. It’s not their fault; they don’t get to watch Chinese TV like us Chinese watch American TV, because most Chinese movies and TV shows suck, and the government channels are too cliche. I really want to show something normal to people who want to know a real China, not through a colored lens, no slant, no drama… Oh there WILL be some drama, of course–drama is a part of reality–but not all of it.
John: How long have you been doing No Drama Real China?
Rachel: In September 2011, i bought a small camera and got started.
John: What are your plans for the show, if it becomes more and more successful?
Rachel: 1) Make the program better and broader. If it gets successful, which means there will be sponsors and volunteers, or i can afford to hire somebody, I will get voices from all over the country, which will make it more real. If I could get some better equipment, I could make the production quality better too.
2) Make the program more diverse and more targeted. My group could do interviews in a particular region in China, or focus on particular issues (still no politics though), or do documentary videos, always keeping the style of putting real people’s real lives and real voices in front of the camera, with as little explanation or interpretation as possible. Because once I talk it’ll become subjective, the people will become the way I see them.
3) Use the program to collect data for cultural and commercial research. Maybe it could be a tool for consulting.
4) Actually I just want to keep doing what I believe in and see where it goes. Life always surprises me!
John: Can you describe the process you go through when creating a new episode?
Rachel: Collect questions, interview people, edit, translate, put music in, make an intro video, sometimes I need to find or make some extra material (like the Beat It! Dance). Then, upload, AND THEN do a little marketing. That’s something… it’s so difficult to get people interested in my interviews while sex and drugs stuff get people’s attention. Many thanks to my friends and friends’ friends who helped me a lot by sharing my videos.
John: Are all those people you interview your friends? If not, how did you approach them? (How do you know the old lady?)

No Drama Real China host Rachel Guo
Rachel: Those are my friends, family, people I meet everywhere in my social life, and some random strangers too.
Again, thanks to my friends who support me and introduce people of different occupations to me to interview. It’s so difficult to get strangers to be open to you in China, to be natural in front of the camera, and to share their real feelings. For example, when I travel on the train everyone is stuck together in a small space, so I can do a small warm-up and explain what I am doing, win some trust, and then interview.
The old lady who is a little deaf is my grandma. 🙂
John: Is there a way to submit questions for the show?
Rachel: People usually leave their questions in the comment sections on the ND/RC YouTube page, I check it every day and answer every comment. I’ve also just started a FaceBook page, so please join me there too! I think a lot about the questions people give me; it’s really very helpful. I hope I can have more ways to reach people, so people will feel its easy and fun to ask questions.
John: Is there anything else you’d like to say to your non-Chinese viewers?
Rachel: This channel is actually made for non-Chinese viewers. That’s why it’s on YouTube. I want to say THANK YOU to all people who appreciate it and share it. Your words, your suggestions, your questions and ideas are the greatest support for me. One of my friends works in the U.S. State Department, and he says it’s so difficult to make the right decisions for America-China-Asia issues, because the media only shows the drama, some voters are misled, and they don’t see how important this is. I want everybody to try not to be part of the problem but the solution. That’s what I also want to say to people who hate my program: PLEASE always give truth another chance!
John: 有没有什么想对中国观众说的话? [Is there anything you want to say to your Chinese viewers?]
Rachel: 多谢大家的支持,相信懂得汉语的观众朋友们会看到画面背后更多有趣的信息。欢迎参与与分享。 [Thank you, everyone, for your support. I’m sure viewers that understand Chinese will notice that there are even more interesting details behind the videos. You’re welcome to participate and share.]
09
Mar 2012Types of Tone Mistakes
As a learner of Chinese, you’re going to make mistakes with your tones. A lot of them. It’s unavoidable. It can be helpful to reflect on the kinds of mistakes you’re making, though, because it can help you realize that despite all the mangled tones, you’re actually making progress.

No, I’m not just talking about the stages of learning tones which I’ve written about before, I’m talking about mistakes which are fundamentally different in nature. As your Chinese gets better and better, you’ll keep making some mistakes, but the types of mistakes you make will change.
So without further ado, here are the 4 main types of tone mistakes:
Mistakes of Control
When you first start studying Chinese, you have no idea at all how to properly make the tones. Even if you can hear a difference, you can’t do it yourself. Or maybe you can hear and repeat it immediately after, but then quickly forget how to do it. This is all part of the process of learning tones.
Don’t think this type of mistake is only for beginners, though. Even after you can accurately produce individual tones in isolation, you’re going to have problems with tone pairs and tones across whole sentences for a while. (For me, the most insidious of these was the 3-2 tone swap error.)
Relax! Persistent effort will totally pay off. No one masters tones in 2 weeks. It takes time.

Mistakes of Ignorance
Sometimes you don’t know the tones of the words you want to use. Don’t worry; it happens to all of us. If you only use words for which you’re 100% sure of the tones, then you’re doing it wrong. Not knowing the correct tones but blundering on through anyway is just part of the learning experience.
The key here is that you eventually make the effort to learn the proper tones for the words you’re unsure of. This takes time, patience, and lots of dictionary lookups. Eventually your accumulated tonal knowledge (and proper execution) make you start sounding less like a “stereotypical foreigner” when you speak Chinese.
Mistakes of Memory
For me, this is always the most frustrating tonal mistake of all. Have you ever been sure that you know the right tones for a word, and always took care to properly pronounce that word, but then found out much later that the tones you thought you had down cold were actually wrong?
I remember when I first came to China I was sure that the word for “north,” 北, was pronounced “*bēi” (first tone rather than third). I was horrified to finally learn the truth. I’d been confidently saying it incorrectly for half a year. Nothing to do but make the mental correction and move on. Memory is never perfect, and you can’t really avoid these mistakes.

Mistakes of Influence
This one can also be frustrating, but I’d say it’s more confusing than anything. So what happens when the dictionary says a word is pronounced one way, and your friend tells you it’s pronounced a different way? Or two friends give you contradictory information, but it’s all different from what the dictionary says? Sadly, these issues invariably plague the intermediate learner of Chinese.
There are several reasons that these discrepancies arise. First is regional variation. Different parts of China pronounce some words in different ways, and although at times you’ll hear unquestionably “non-standard Mandarin,” at other times it’s unfair to call a certain regional variation “wrong” or “right” (although some Beijing have no problems at all doing this).
Second is the widespread use of dated reference materials. Printed dictionaries simply aren’t keeping pace with the rapidly evolving language of the Chinese people. New words are created, and pronunciations change (sometimes just the tones) relatively quickly.
Third is a cultural tendency to submit to the recognized authority (i.e. the outdated reference materials). So you often get exchanges like this:
A: How do you pronounce the character 血?
B: “Xuě.”
A: But the dictionary says it’s either “xuè” or “xiě.”
B: Oh yes, that’s right.
A: But you just said…

You get the idea. But what can you do? Know that dictionaries are not perfect, and no single person can be an authority on a whole language. You’re going to have to assemble your mental map of the words of the language over time, from the mouths of many speakers, not one “omniscient” teacher.
Don’t be afraid of making mistakes. They’re inevitable, and they help you learn. But as long as you’re going to be making these mistakes, you might as well look a little closer and gauge how your language ability is growing and your unruly tones are slowly but surely being tamed.
06
Mar 2012No Drama, Real China
A friend of a friend has started a new video series in Beijing called No Drama Real China. The host is a Chinese girl named Rachel Guo. The concept is simple: ask a cross-section of Beijing’s population some interesting questions related to Chinese culture, and present the hodge-podge of answers in all its heterogeneous glory for the benefit of cross-cultural understanding (so, with subtitles, obviously). The result is interesting, funny, and perhaps even educational (especially for all you students of Chinese).
Here are some of my favorites:
What Are Chinese People Afraid Of?
For the linguistically sensitive, this next one has Rachel dropping what appears to be a few strangely out of place gratuitous F-bombs, but apparently she’s quoting a rather rude online user:
Do Chinese People Eat Everything???
(The video above also has a particularly amusing scene where the old lady can’t seem to understand the clear Chinese of the interviewer.)
No Drama Real China shows a lot of promise! Please have a look at these videos. If you can’t access YouTube, there are also a few on Youku.
Keep up the good work, Rachel!
02
Mar 2012Dict.cn does Shanghainese
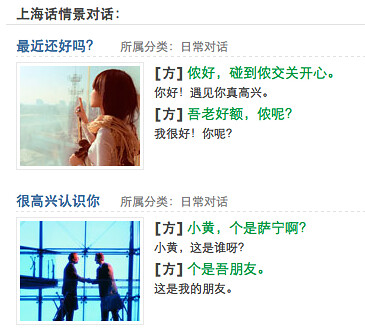
I was recently informed (thanks, Mark!) that Dict.cn, one of the popular, free online Chinese-English dictionaries, now offers Shanghainese content. I was pleasantly surprised to see a big list of mini-dialogs in Shanghainese! The bad news is that the dialog text is in characters (切 for 吃, etc.), and there’s no IPA or other phonetic transcription. They only have one speaker doing the audio, but there’s audio for every sentence (tip: mouse over the little speaker rather than clicking on it), so that’s not bad.
I asked my wife what she thought about the speaker’s accent. She said it was 新派上海话 (the form of the dialect spoken by modern young Shanghainese), and she felt that the female speaker was too 嗲 (cutesy-sounding). But, hey… it’s Shanghainese.
I also recently did a little research on Shanghainese lessons in Shanghai. Interestingly, some of the schools that I know used to offer Shanghainese classes no longer do. Is the demand dropping? Have any readers out there taken Shanghainese lessons at a local university?
28
Feb 2012Unmixing Chinese and Japanese fonts on the iPad and Mac OS
Recently an AllSet Learning client came to me with an interesting problem: he was seeing strange, slightly “off” variations of characters in his ChinesePod lesson, “Adjusting the Temperature.” Once upon a time I studied Japanese, so I could recognize the characters he was seeing as Japanese variants:
What he saw: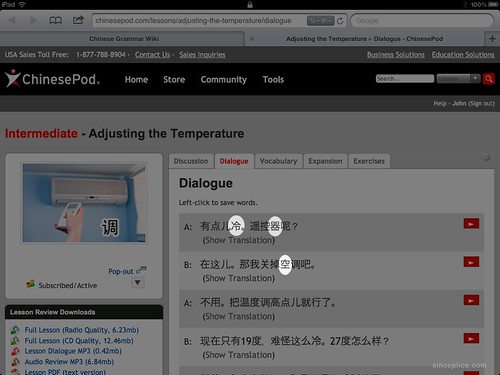
What he expected to see: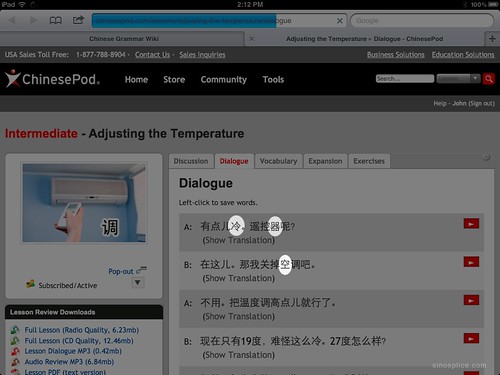
[If you really care about the tiny discrepancy, you may need to click through and enlarge the screenshot to see the difference. I’m not going to focus on including text here, because that’s exactly the nature of the problem: the text is subject to change based on your system’s font availability.]
The really strange thing was that he was experiencing the exact same issue on both his 2010 MacBook and on his iPad 2. In troubleshooting this problem, I discovered that my client was running both an older version of iOS (4.x) as well as an older version of Mac OS (Leopard). I was experiencing neither on my 2008 MacBook (running Snow Leopard) or on my iPad 2 (iOS 5.x). But his system had all the required fonts, and switching browsers from Safari to others did nothing to solve the problem. So I concluded it was simply a system configuration problem.
Fixing the issue on the iPad
Here’s the fix. On the iPad, go into Settings > General > International (you might need to scroll down for that last one). You might see something like this:

Note that in the order pictured above, Japanese (日本語) is above simplified Chinese (简体中文) in the list. This is crucial! That means that if English fonts are not found for the characters on a given page, the system is going to match characters to Japanese fonts next.
So to fix this issue, Chinese should be above Japanese. The thing is, there’s no obvious way to change the order. The only way I found to do it is to switch the system language to Chinese, then switch back to English. [Warning: your entire iOS system interface will switch to Chinese when you do this; make sure you can read the Chinese, or you know where the menu position for this settings page is before you switch!]
(Hint, hint!)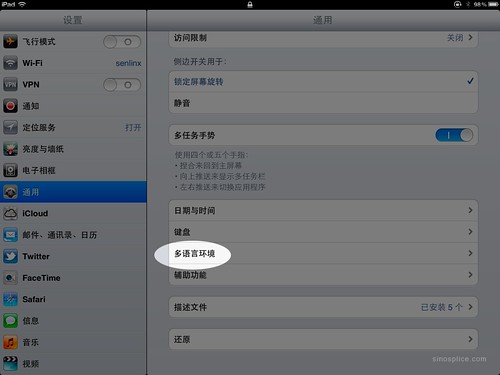
Switching to Chinese makes the Chinese jump to the top of the list, then switching back to English makes English jump back above that, leaving Japanese below Chinese.
You should see something like this when you’re done:

Fixing the issue on Mac OS X
The exact some issue applies to Mac OS X system preferences. Go to: System Preferences… > Language & Text > Language.

This time, though, there’s an easier way to rearrange the order. Simply click and drag:
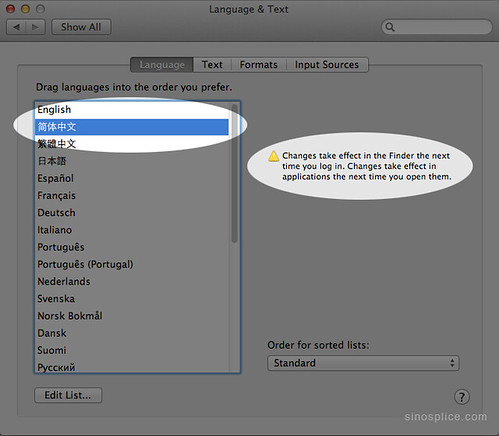
Notice the little message on the right about when the changes will take effect.
Does this really matter?
In the grand scheme of things, not really. It’s actually good to have some tolerance for font variations. But the detail-oriented may find this particular issue quite maddening. It’s good to have a simple way to fix it.
So why didn’t I have the issue, and he did? Well, I had at some point tried switching the system language to Chinese, on both my MacBook and on my iPad, but I later switched them back to English. So without even trying to, I had taught my system to prefer Chinese over Japanese. The problem appears when English is the only language ever used, and the system doesn’t know what to give preference to. In my client’s case, you would think that adding a Chinese input method might clue in the system, but apparently Apple isn’t quite that on the ball yet.
24
Feb 2012Translations of Butterfly (Linguistic Differences)
Via John Biesnecker:

Sorry, I can’t credit the original author because I don’t know it. I added the Chinese translation into the mix (蝴蝶).
This is especially hilarious to me personally because I know very little German, but I actually learned the German word “schmetterling” long ago by chance, and found the word enormously amusing. Guess I’m not the only one!
21
Feb 2012Speaking a Foreign Language without Translating
Friends of mine have asked me many times: can you really speak Chinese without translating it first in your head? And when I answer yes, the follow-up question is: but how can you get to that point? I have to translate everything!
There’s both an implied lie and a rather direct lie in that follow-up question.
“But how can you get to that point?”
The problem is that it’s not a “point.” There’s no instant when you can suddenly stop translating completely. Rather, you stop translating longer and longer stretches of language. Over time, what was once long stretches of language which needed to be translated, interspersed with only occasional words you understood, eventually becomes long stretches of language which don’t need to be translated, interrupted only by the occasional need for translation.
“I have to translate everything!”
Do you? Do you have to translate 你好 (“hi”)? Do you have to translate 谢谢 (“thank you”)? To tell someone you don’t want something, do you have to consciously translate “I don’t want it” into 不要? Or do you just blurt them out?
Sure, when you first start out, you have to learn these expressions, and then you do have to translate them when you first start using them. But especially if you’re in the target language environment, their usage starts to become automatic quite quickly. I observed 你好 and 谢谢 becoming automatic for my parents during their recent two-week visit. They don’t speak a lot of Chinese, but even they were “speaking without translating” relatively quickly.

With enough practice, more and more words and phrases become automatic. You don’t feel your brain shirking its translation duties; it just happens so naturally. When you finally realize it’s happening, that you’re starting to understand and process not just individual words and short phrases, but whole sentences without even translating them, it feels a little surreal. It’s kind of like one of those Escher works. You really can’t pinpoint at what point the bird became a fish.
But the truth is, if you’ve been not just “studying,” but using your language skills for any length of time, the ebbing of conscious translation has already begun. If you try, you can sort of feel it. It’s this weird sensation called “fluency” creeping up on you, ever so subtly.
15
Feb 2012Ideas for Moms’ Trips to Shanghai
I’ve been away from blogging recently as my parents were here visiting their new granddaughter. It was only their second trip to Shanghai, and before they got here I spent some time wracking my brains for good things to do. There are tons of things to do in this city, but so very few of them are obvious. The best ideas always seem to occur to me too late.
Mary Ann, an AllSet Learning client of mine who is a mother herself, had recently compiled a list of mom-friendly activities for her own mother-in-law’s visit, and she kindly shared it with me, along with her comments. I thought some readers might find it useful, so here it is, with her persmission:

– Urban Planning Museum. I find it interesting, and I think most people who like cities are usually into it. The top floor now shows a short movie which shows a 360 panoramic view of Shanghai from Hongqiao to Pudong. I haven’t seen it but my kids and visitors have and everyone has liked it!
– “Ghost Market.” That Antique market on early mornings on Saturdays and Sundays near Yuan gardens. I find it fascinating that so many people come to Shanghai from the countryside to sell ceramic shards. I like to watch the background social scene but picking through some of the stuff is fun too.
– Old China Reading Room on Shaoxing Lu. Restful place to browse books and drink tea (nice Austrian cakes at Vienna Cafe nearby)
– Glasses Market above the Railway Station. Since your parents aren’t shoppers, the one market that they might be able to get something at and take part in Shanghai commerce madness is the Glasses Market. They should bring a prescription with them from the U.S. and get some glasses made. People with glasses can always use a spare and much much cheaper than in Europe, I’m assuming the same in the U.S. My friend’s ophthalmologist sends all her patients to Bright Eyes Optical (stall 4056). I have taken people to get glasses done there and they were all were happy afterwards. Speak to Linda; she speaks English (in case your parents go on their own).
– Historic houses on/around Sinan Lu. Visit the ones converted into museums.
– Walking Tour. Yes, I’m insisting on this! And no, you can’t walk them around with an app instead! All parents like this sort of thing. Of course skip the cheesy ones but do go for the historian-led ones, or at least the ones led by guides with more street cred. The highly recommended guy who does the tours of the Jewish Heritage sites is an Israeli journalist/historian who runs shanghai-jews.com.
– Hang out at a Tea House. You probably know of a good one. [Actually, not really!]
– Foot Massage or other treatment at Xiao Nan Guo (Hongmei Lu). Have you been here? I’ve only eaten there a few times. The spa part of it has all spa typical treatments available PLUS there’s entertainment, which I think is daily. I think it would be great to take them to a foot massage while watching a show of russian dancers. Why, they may ask? Well… why not? Sounds kooky but that’s the point. Anyway, supposed to be pretty affordable so it could be something to do.
– Propaganda Poster Museum.
– I accidentally came across a place in the Old town where they sell books by weight… quite amusing. Have you seen this? Isn’t one of your parents a librarian? Might be worth a bit of a hoot if in the area…
– Spin Ceramics on Kangding Lu. Something for themselves or for a gift. Do you know this place? Fab stuff at great prices.
Sadly, my parents only got to do the first thing on this awesome list, but they did have a great time (despite Shanghai’s inhospitable winter weather). Hopefully someone else will find it useful.
Another client recommended Shanghai Pathways for tours, but we ended up just not having time for so many activities.
If you’ve done any of these things or have anything else to add, please leave a comment!
Related Posts:
– China Lite (2011)
– Micah and John on Touring Shanghai (2008)
31
Jan 2012Three Simple Uses of the Other “Ma” on a Bag
I recently wrote about my personal experience with the particle 嘛 (not 吗), and how a dictionary entry helped me get a feel for how the particle is used. That dictionary entry, again, is from the Oxford Concise English-Chinese Chinese-English Dictionary (blog post here):

> 嘛: ma (助) 1 [used at the end of a sentence to show what precedes it is obvious]: 这样做是不对~! Of course it was acting improperly! 孩子总是孩子~! Children are children! 2 [used within a sentence to mark a pause]: 你~,就不用亲自去了。 As for you, I don’t think you have to go in person.
Not too long ago, I encountered this little coin purse/bag, which offers three very concise uses of our particle 嘛:

The text is as follows (broken into three lines to make it easier to discuss):
> 1: 钱嘛
> 2: 纸嘛
> 3: 花嘛
OK, now clearly, this is the same 嘛 particle. But what does this actually mean??
First, “钱嘛” means something like, “it’s money,” as in, “we all know what money is, and what it’s for.” This could also have been expressed more verbosely by: “是钱嘛” or even as: “不就是钱嘛” (“isn’t it just money”??).
Second, “纸嘛” quite simply means, “it’s (made out of) paper (as we all know).” Duh. “It’s just paper.” This usage is basically the same as the first.
Last, we have “花嘛,” which is slightly different because it’s a verb. Still the idea is quite similar. It’s for spending. You might translate this into English as, “so just spend it!” Another way to put it in Chinese would be, “想花就花嘛” (if you feel like spending it, just spend it).
The words on this bag strike me as a Shanghainese, female way of looking at money. But maybe that’s because the bag belonged to a girl I know…
Related Grammar Links:
– Expressing the Self-Evident with 嘛 (Chinese Grammar Wiki link)
25
Jan 2012Personal Experience with the Other Particle “ma”
I remember quite distinctly the way I learned the sentence-final particle 嘛. I had only been studying Chinese for a little over a year, and thus was quite familiar with the yes/no question particle 吗, but not this new 嘛, which seemed a bit more complex. I might have studied it before and just ignored it, but once I was on the streets of Hangzhou and hearing it all the time, I knew it was time to start figuring out what this 嘛 was all about.
So I broke out my trusty old Oxford dictionary (we still learned Chinese from actual books in those days), and looked up 嘛. Here’s what I found:
> 嘛: ma (助) 1 [used at the end of a sentence to show what precedes it is obvious]: 这样做是不对~! Of course it was acting improperly! 孩子总是孩子~! Children are children! 2 [used within a sentence to mark a pause]: 你~,就不用亲自去了。 As for you, I don’t think you have to go in person.
I know some people hate learning from dictionaries, and grammatical concepts especially can be difficult to learn that way, but for me this explanation was a revelation: used at the end of a sentence to show what precedes it is obvious.
I think a lot of us have personal experiences in which we acquire a new word, and the memory of those specific vocabulary acquisition experiences stay with us long after we internalize the words themselves (one of my own personal examples is my attempt to buy a bug zapper light). This is quite natural, and it’s also one of my key misgivings about SRS. The way we naturally acquire language stays with us and reinforces the entire process, tightly binding words, meaning, and real-world experience. SRS (or simple word lists in general) can’t really offer this deep of a connection.
But back to my dictionary example… How is this any different from an SRS learning method, divorced from a real-world connection? Logically, I feel like looking up a word in a dictionary isn’t much different from being presented a word electronically. Sure, there’s the tactile interaction with the book, and the effort involved in getting out the book in the first place, and the act of physically flipping to the appropriate page, then locating the appropriate headword with my finger. How much “momentum” do these behaviors actually amount to, in a learning context?
Although I can’t think of many compelling instances besides my 嘛 example, I definitely feel that there are words which I learned (and not just “learned,” but developed a strong connection to) largely due to a dictionary. This leads me to two important questions:
– How many of you out there have clear memories of really learning a word or expression through a dictionary? What was it that made it so memorable?
– How many of you out there have clear memories of really learning a word or expression through SRS? What was it that made it so memorable?
For me, I think the dictionary’s explanation struck me so poignantly because I had actually already expended a significant amount of mental energy on the use of 嘛 but I had not yet been able to express the ideas concisely, and the 嘛 entry did just that, right when I needed it.
Please share some of your own personal learning experiences in the comments. I’m very interested to hear what you have to say.
Related Grammar Links:
– Yes/No Questions with 吗 (Chinese Grammar Wiki link)
– Expressing the Self-Evident with 嘛 (Chinese Grammar Wiki link)
22
Jan 2012A New Resource for Chinese Grammar

It’s hard to believe I’ve been working on this project for a whole year, and also thinking about it, in some form or another, ever since founding AllSet Learning. Today, I’m quite happy to finally release the AllSet Learning Grammar Wiki.
What is it? Well, in a nutshell, it’s a mini-Wikipedia devoted entirely to Chinese grammar. Think comprehensive, think interlinked, think referenced. I’ve felt for a while that Chinese grammar has needed its own champion online, and since forming AllSet Learning, I’ve finally got both the need and the means to make it happen and keep it going.
I won’t say too much here; there’s a blog post on the AllSet Learning blog introducing the features and concepts behind the Grammar Wiki. Obviously, you can also just go straight to the wiki and check it out.
There’s not yet any public forum on the AllSet Learning websites, so if you’ve got feedback, feel free to leave it in the comments here. Please do read the AllSet Learning blog post first, though, as it may answer some of your questions. I’d also like to reiterate that the Grammar Wiki is not finished, and I’m not sure it ever will be, but with 500 articles and a good juicy set of grammar points it’s now at a point where it’s clearly useful to learners, so it’s time for it to emerge from its cave and be exposed to the rest of the world.
Finally, I’d like to thank the AllSet Learning interns who, over the past year, have helped make the Chinese Grammar Wiki a reality: Lucas, Greg, Hugh, and Jonathan. You guys were an immense help. Thank you also to all bloggers and friends who help spread the word by linking to the Chinese Grammar Wiki. Please help spread the word!
That’s all for now… Happy Chinese New Year!
20
Jan 20122012, Year of the Dragon
Well, it’s almost Chinese New Year, and this new one is the year of the dragon. It didn’t escape too many Chinese designers’ notice that it’s pretty easy to turn a “2” into a dragon, so lately we’re seeing a lot of designs like these:



Here’s one that’s a little different:

Not as fun as last year, though! I’m still not a huge fan of this holiday, and it’s getting harder and harder for this country’s residents to go home to it celebrate it properly, but it’s still an interesting time of year.
Happy Chinese New Year! 新年好! (The new year starts Monday.)
17
Jan 2012Shanghai’s “Fake Collars”
I’ve been living in Shanghai a while now, but it wasn’t until just recently that I ever heard of Shanghai’s “fake collar” shirts (假领子). Technically, the collar is not fake at all; the collar helps to create the illusion that the wearer has on a full shirt under a sweater, when in fact he/she does not. They even have little straps on the sides to keep them in place!
Naturally, this calls for pictures:



According to this website, these “fake collars” are a Shanghai creation. My mother-in-law (a Shanghai native) proudly explained to me that they were invented to preserve a well-dressed appearance in a truly Communist age when neither clothing nor fabric were cheap. “We all wore them,” she said. “We could buy quite a few jia lingzi for the same price as one shirt.” When worn under a sweater, they create the impression of full, proper attire. Quite innovative! (Reminds me of all the ways I used to fake having taken a shower when I was little.)
These things were common from the 60’s through to the 80’s, but have long since fallen from favor, now that ordinary people actually have a little bit of money. Apparently you can still buy them in Shanghai, somewhere on Sichuan Road. I’ve gotta get my hands on one of these. (They also just might make for an interesting souvenir!)